One of the advantages of the built-in functions all() and any() is the simplicity and understandability – at least if the check is small.
When developing software, being nice and understandable is not the only criteria. Often, a big question is “is it fast enough?”. Even if that question can be answered with “yes”, usually there are some conditions when, where and how to use it.
For all() and any() the same applies. They have their own rights to exist – otherwise, Python wouldn’t provide them as built-in functions.
In this small blog post, I will try to give an overview of the performance in different scenarios, and some pointers to help you make your own decisions when you want to use this functions and when it makes sense to write your own functions (or for-loops).
Implementation
First things first: how are the functions implemented in Python?
They both expect an iterable as input, loop over it and check each element. For all(), it breaks as soon as an element evaluates as False (or to be precise, the breaking condition is ’not True’), for any() as soon as an element is evaluated as True:
 |
|
In Python, an interable is any object which can return its members one at a time. To be precise, the methods __iter__() or __getitem__() need to be implemented. This includes the Python classes list, tuple, str, dict and generators.
We only need to test one built-in function to check the performance: Both are looping over all elements in the iterable and breaking as soon as either an element satisfies (any()) or breaches (all()) the Boolean condition.
⚐ Small hint: it is possible to call the functions with empty lists: any([]) will evaluate to False, and all([]) to True. Totally logically if you look at the implementations, but my brain struggles with the different behaviors of the functions: Why is “everything” ok in an empty list, but not “anything”?
I also wanted to run the built-in function against a self-implemented any-function which has the condition hard coded and evaluates the given list against it. I used the condition “is not zero”, which implies the question “are any elements non-zero values?”. My implementation looks like this:
Performance
I wanted to test the built-in functions with different types of iterables, and used list, set and generators. The calls for the any() function are:
My own functions was tested against the original list elements (no generators, no comprehension) , without any changes.
The setup of the provided iterable is simple: I provided iterables were all elements are either 0 or 1. I tested three scenarios: In the best case (for performance), the first element will break the loop, in the worst case the last element will, and the “normal” case will break in the middle – so in all three cases the return value will be False.
Setup clear? Good. Now let us check the performance!
Short, but important recap: the any() function can stop as soon as “any element fits the condition”. In our case, as soon as an element is one and not zero. In the best case, this means only a single element has to be evaluated, worst case, all elements have to be iterated over and checked.
Let us start with the worst case:

We can see, that the generator needs the most time (0.06ms with a list of size 1’000), and the self-implemented function is the fastest (0.03ms with a list of size 1’000) – twice as fast as the generator.
For me, it is not a surprise to see that the self-implemented method is faster: It doesn’t have to go through two lists (first to transform it into True/False values, then inside the built-in function). What did surprise me is that the generator takes double time and is slowest. I did not expected that.
That the set is faster than list for bigger sizes makes sense to me, because the second loop (the loop inside any()) will be smaller: If reduced to True and/or False values only, it consists maximal of two elements in a set-comprehension, but the same length as the original list when using list-comprehension.
Still, the set implementation is 1/3 slower than the self-implemented function. For time-sensitive applications, and big lists, this has an impact.
Now, this was the worst case, let us see if there is a difference if we can break early, using the “normal” case:

The self-implemented function only needs half the time it did for the worst case – makes sense, because it can break after half the elements. This implies, my test setup is working ;)
Now, we look at the different iterables provided to the built-in function and we see something interesting: the generator is becoming faster! Before, the generator took 50% more time compared to the set iterable. Now, in the “normal case”, the generator takes 25% less time than the set version.
If we think about it, it again makes sense. As mentioned in the worst case, the list and set version need to iterate twice over the list. The generator only once, but seems to be slower during the loop or evaluation inside the built-in function.
Nice to point out: the runtime of the set is the same – again, this is logical because it still has to run through the original list, and provides a list of maximal two elements (True and False) to the built-in function. The runtime of the list is almost the same, just a little bit faster because the second loop can be stopped after half the elements.
After this realization, the results of the best case scenario shouldn’t be a surprise:

The run time of the list and set version remain the same, but now, the generator version is almost as fast as the self-implemented function. I did a sneak a peek and zoomed in: any_none_zero_values() takes around 500ns and the generator version 900ns.
Finally, I also looked at the worst case scenario for small lists:
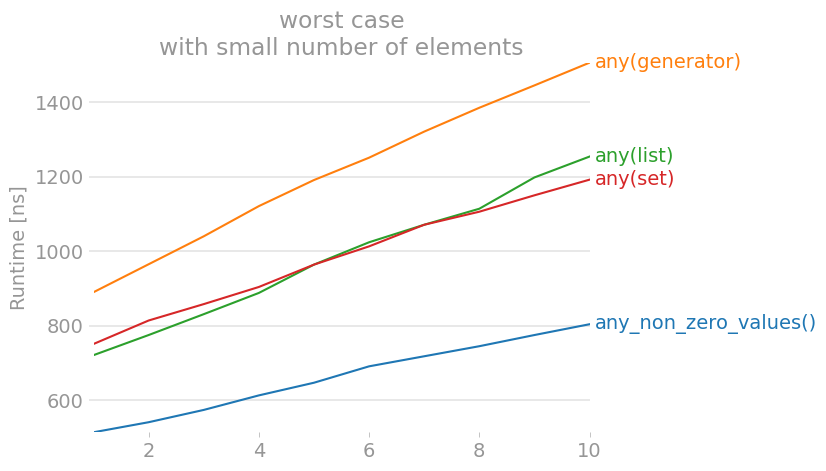
I didn’t expect any changes from the worst case with many elements, but there is something I would like to point out: With a small number of elements (smaller than 6 I think), the list version is faster than the set. Which implies that checking “is this element already in the set” is slower than the few extra elements to check.
Performance-wise, the gap is slightly bigger for small numbers of elements: With only 10 elements, the set version takes double the time of the self-implemented function – for 1’000 elements it is only 1/3 slower.
Conclusion
Generally speaking, if you develop a time-sensitive application, you should think about implementing your own functions with “hard-coded” conditions.
If you want to use the built-in functions – for example because you like the readability – you can still improve the performance:
I would highly suggest to use list (small size) or set (otherwise) comprehension before the call, if you use it as a check. For example, if you check that your list doesn’t have any None values, and if it has, you raise an exception. In this case your expected behavior is that the call needs to run through all elements and normally will not “break early”.
Other way to identify the right choice of iterable:
If you expect that all() returns True and/or any() returns False, use set-comprehension. If you expect the opposite outcome, use generators to reduce time.
Appendix
I used the Python package perfplot for the visualization with the following settings: